ビンパッキング問題でGoogleと対決!?
2026/04/17
written by 先田 力哉
ビンパッキング問題でGoogleと対決!?
ビンパッキング問題とは
生産スケジューラFLEXSCHEは様々な製造業で使われていますが、業種によっては材料や製品が
切断できるが、合体できない
という性質を持っていることがあります。
たとえば、
- ロール紙
- 電線
- クレーンブームの鋼管(ラチスパイプ)
などです。
その場合、
様々なサイズの部材から、必要な寸法分を切り出して使用する
ことになりますが、その際、部材ロットをいい加減に選ぶと、半端な切れ端が残って無駄になってしまう可能性があります。
具体的な例で考えてみましょう。
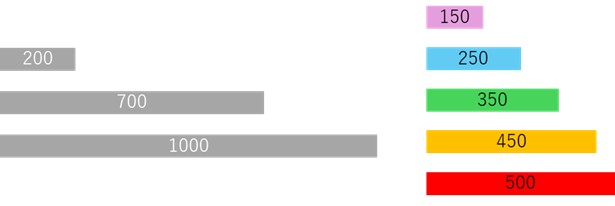
上の図で、左側は材料として使用する部材、右側はそれらから取り合わせて製造したい製品だとします。材質はどれも同じなので、寸法が足りるなら、品質上は取り合わせ方は自由です。
これらを下のように
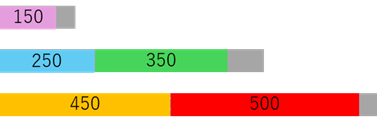
と取り合わせると、50 100 50 という半端な残り(端材)が発生します。
一方、取り合わせ方を
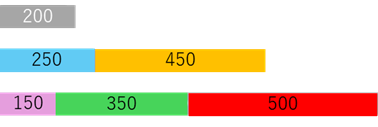
とすると、端材は発生せず、元の部材の200がそのまま残ります。将来、新たなオーダーが来たときに残った部材を使うチャンスもあるでしょう。
これらの2つを比べれば、下の方が良いですよね。
部材と製品の数がこれくらいなら、頑張って考えれば良い組合せを思い付けますが、数百、数千、となると、ちょっと(かなり)(めちゃくちゃ)大変です。
数理最適化の分野では、このような取り合わせ問題を「ビンパッキング問題」といいます。
「ビン」は入れ物です。以前このブログで「ダブルビン方式」を取り上げましたが、そのビンと同じです。
ビンに、様々な大きさの「アイテム」を、ビンの容量以内で詰め込みます。使用するビンの数をなるべく少なくするように全てのアイテムを詰め込む方法を考える問題、ということで、その名前になっています。
ただし、通常のビンパッキング問題では、ビンの大きさはどれも同じ、とされていますが、製造業では、使い切らなかった部材もまた次回使えばいい、ということが多く、その場合は上で考えたように、引当て可能な部材のサイズは様々、ということになります。これは「可変サイズ ビンパッキング問題」と呼ばれているそうです。
可変サイズビンパッキング問題をどうやって解く?
では、この「可変サイズ ビンパッキング問題」をどうやって解いたらよいのでしょうか?
なお、ビンパッキング問題は、サイズが固定でも可変でも、いわゆる「NP困難」で、データ量が多くなると、組合せが多くなり、実用的な時間で最適解を得るのは難しいとされています。
しかし、FLEXSCHEには、最適解ではなくても、それなりに良い解を出すことが求められます。「わかりませんでした」では、日々の製造を実行できないので、ユーザーが困ってしまいます。
FLEXSCHE GPのサンプルでは「逐次ナップサック」
実は、FLEXSCHE GPのサンプル集には、「ロット引当て(GP上級オプション)ナップサック」というサンプルが含まれていて、その中で、ある方法でそれを実現しています。
このサンプルでは、ビンに当たるのが供給側のロット、アイテムに当たるのが需要側のロットで、それらの間を引当てます。
その際には、1つの需要ロットが複数の供給ロットにまたがらないように、かつ、1つの供給ロットに引当てられている需要ロットの合計数量が供給ロットの数量以下となるようにする必要があります。これは絶対に守る必要がある制約条件ですが、それはFLEXSCHE GPに用意されているスケジューリングメソッド「(自動)ロット引当て」で簡単に守ることができます。
制約を守ったうえで、さらに端材が少なくなるように組合せるために、このサンプルでは「逐次ナップサック」として解いています。
「逐次ナップサック」と言われても、何のことだかわかりませんよね。
実は「逐次」+「ナップサック問題」なのですが、まずナップサック問題から説明しましょう。
ナップサック問題とは
ここでいう「ナップサック」は、皆さんよくご存じの、リュックサックみたいな袋のことです。ただし、3次元の袋ではなく、1次元で、伸び縮みはしない、という仮想的な袋です。ナップサックには容量があり、その容量の範囲内で複数の品物を入れることができます。品物にはそれぞれ重さがあり、品物の重さの合計がナップサックの容量以内なら、それらの品目をナップサックに入れることができます。
さらに、品物にはそれぞれ価値が定められています。ナップサックの容量以内で、価値の合計を最大にするように品物を選び出すのが「ナップサック問題」です。

上の部材の例に当てはめると、1つの部材が1つのナップサックで、容量は部材の長さです。つまり、1つの部材に、その長さの範囲内で各製品を選ぶのがナップサック問題です。もちろん、全ての製品を入れることができるわけではありません。

逐次ナップサックとは
「逐次ナップサック」では、1つの部材に対して引当て相手を決めたら、次の部材と残りの製品で同様に引当て、それが終わったらさらに次の部材と・・・というように、ナップサック問題を順番に解いていきます。
そのようにすれば、全ての部材に対して引当て相手を決めることができます。もしも製品が残ってしまうなら、新たに部材を調達する必要がある、と判断します。
逐次ナップサックとして解くメリット・デメリット
逐次ナップサックとして解く場合は、ビンパッキング問題を分割して解くことになります。
NP困難な問題は、規模が大きくなると多項式以上のオーダーで所要時間が長くなります。逆に言えば、問題を分割することで高速化できる可能性があります。
さらに、ナップサック問題もNP困難とされてはいますが、動的計画法(DP)を使って高速に解く方法がよく知られています。それどころか、FLEXSCHE GPには、ナップサック問題を解くtakt関数があります。したがって、ロット引当てメソッドでその関数を使って相手を選ぶことで、簡単かつ高速に、逐次ナップサック問題として解くことができるようになっています。
しかし、その一方で、全体を(可変サイズ)ビンパッキング問題として解くのに比べると、全体最適ではなく逐次部分最適ということにはなります。
最近の最適化ソルバーならどうなる?
ならば、最近進化の著しい最適化ソルバーで解いたらどうなるのでしょうか?
ということで、試してみました。
Google OR-Toolsという無料のオープンソースソフトウェアがあります。非常に優秀で多くのコンテストで金メダルを獲得した実績があるとのことです(ただし、そう教えてくれたのはGoogle検索のAIモード(Gemini 3)ですけれど)。
Google OR-ToolsはPythonでも使えます。ソースコードもGeminiに作らせちゃいましょう。
プロンプトは
ortools でビンパッキング問題を解くには
さらに、ビンの容量が異なる場合はどうすればいいですか
ビンの容量とアイテムの重さのデータファイルを取り込んで、ビンパッキング問題を解いて、結果を出力するプログラムのソースコードはどうなりますか
データファイル名をpython実行時の引数で指定する場合はどうなりますか
といった具合です。
すると、混合整数計画問題(MIP)のソルバーで解くコードが示されました。
この結果を拡張子 .py で保存すればPythonプログラムのできあがりです。実に簡単です。いい時代になりましたね。
混合整数計画問題(MIP)とは
なお、混合整数計画問題というのは、
- 制約条件 1次の等式または不等式
- 目的関数 1次式
- 変数 実数または整数
という形式で表現できる問題のことです。実数と整数が混在しているので「混合」です。
Geminiのコードを見ると、変数は、
- アイテムとビンの1:1の組合せ(二次元配列)に対して、格納されるかどうか(Bool値)
- 各ビンが使用されるかどうか(一次元配列、Bool値)
の2つとなっています。
ちなみに、変数が実数の場合は「線形計画問題(Linear Programing : LP)」と呼ばれており、解くのは比較的簡単です。
しかし、変数の中に整数が含まれてMIPになると、解くのが難しくなります。それでも、ある程度の規模までは解くことができます。
Geminiからの返答にも
アイテム数が数百を超えると MIP は遅くなります。その場合は Google OR-Tools CP-SAT ソルバー への移行が推奨されます。
との言及がありました。
なお、CP-SATというのは、「制約プログラミング(CP)」と「充足可能性問題(SAT)」を組み合わせた高度なソルバーで、内部的に様々な工夫が施されています。それらの工夫により、より規模の大きな問題でも解くことができますよ、とAIは言っているようです。
とはいえ、まずはシンプルにMIPソルバーで試してみましょう。
問題の準備
早速試したいところですが、その前に、解くべき問題を用意しなければなりません。
FLEXSCHE GPサンプル集のデータではデータ量が小さく、実力を測れそうにありません。もっと大きなデータが必要です。
そこで、FLEXSCHE GPで、乱数を使って問題を自動的に作成して、それをCSVに出力して、Pythonプログラムに投入することにします。
もちろんFLEXSCHE内でも上で説明した逐次ナップサックで解きます。
そうすることにより、それぞれで解いて、パフォーマンス(解の質&所要時間)を比較することができそうです。
FLEXSCHEでの問題生成
ビンはFLEXSCHEの供給ロット、アイテムは需要ロットに相当するので、ビンを入荷オーダー、アイテムを出荷オーダーとして生成することにします。
品目はどれも同じで、納期も同じにしておきます。
出荷オーダー(アイテム)は1000個で、数量は100~999の範囲の整数で一様に分布させます。
入荷オーダー(ビン)は150個で、数量は{3000, 4000, 5000}のいずれかです。
なお、アイテムの数量の下限を100にしたのは、数量の小さいアイテムがあると出来の良くないアルゴリズムでも隙間を埋めてしまって差がつかなさそうだから、です。
具体的な「takt式」(FLEXSCHE GP固有のプログラミング言語)は、以下の通りです。
$item := Item.FromCode('A'),
$dueDate := #20260201#,
// 出荷オーダー生成
LongList.Make(1,1000).ForEach([
$order := Order.Create('S' + $_object.ToString('04'), $item, Long.Random(100,999,RandomEngine.MT), OrderType.Shipping ),
$order.LatestEndTime := $dueDate
]),
// 入荷オーダー生成
LongList.Make(1,150).ForEach([
$order := Order.Create('A' + $_object.ToString('04'), $item, Long.Random(3,5,RandomEngine.MT)*1000, OrderType.Arrival ),
$order.LatestEndTime := $dueDate
])
これをスケジューリングルール内の「プロパティ設定メソッド」で呼び出せば、各オーダーが生成されます。
さらに、FLEXSCHE EDIFで、Pythonコードに合わせたスキーマでCSVに出力して、準備完了です。
Google OR-Toolsの結果
いよいよPythonプログラムに投入!
コマンドラインで以下のように入力します。
python solve_packing.py --items data/item01.csv --bins data/bin01.csv
・・・しかし、結果がいつまでも返ってきません。最適解を出そうとして苦しんでいるようです。やはりMIPソルバーでは荷が重いのでしょうか。
とりあえず、いつ終わってもいいように、経過時間も出力させるように改造しましょう。
といっても、私はプロンプトを入力するだけですが。
実行時間も表示させるには、どうしたらいいですか
するとそのように修正したコードが表示されました。さらに以下の提言が。
もしデータが巨大で計算が終わらない可能性がある場合は、以下のようにタイムリミットを設定することをお勧めします。
計算時間が想定より長い(例:数分以上かかる)場合に備えて、この「タイムリミット設定」も組み込んでおきましょうか?
おお、気が利くじゃないですか。
お願いします
即座に「60秒で打ち切るコード」が提示されました。内容は以下の通りです。
import pandas as pd
import argparse
import sys
import time
from ortools.linear_solver import pywraplp
def solve_bin_packing(items_csv, bins_csv):
# 1. データの読み込み
try:
df_items = pd.read_csv(items_csv)
df_bins = pd.read_csv(bins_csv)
except Exception as e:
print(f"エラー: ファイルの読み込みに失敗しました。 {e}")
return
item_weights = df_items['weight'].tolist()
item_ids = df_items['item_id'].tolist()
bin_capacities = df_bins['capacity'].tolist()
bin_ids = df_bins['bin_id'].tolist()
num_items = len(item_weights)
num_bins = len(bin_capacities)
# 2. ソルバーの宣言
solver = pywraplp.Solver.CreateSolver('SCIP')
if not solver:
return
# 3. 変数の定義
x = {}
for i in range(num_items):
for j in range(num_bins):
x[i, j] = solver.BoolVar(f'x_{i}_{j}')
y = {}
for j in range(num_bins):
y[j] = solver.BoolVar(f'y_{j}')
# 4. 制約条件
for i in range(num_items):
solver.Add(sum(x[i, j] for j in range(num_bins)) == 1)
for j in range(num_bins):
solver.Add(
sum(x[i, j] * item_weights[i] for i in range(num_items)) <= y[j] * bin_capacities[j]
)
# 5. 目的関数: 使用ビン数の最小化
solver.Minimize(solver.Sum([y[j] for j in range(num_bins)]))
# --- 追加機能: タイムリミットの設定 (ミリ秒指定) ---
# [OR-Tools Solver Parameters](https://developers.google.com)
limit_seconds = 60
solver.set_time_limit(limit_seconds * 1000)
# 6. ソルバー実行と時間計測
print(f"計算開始... (アイテム数: {num_items}, ビン候補数: {num_bins}, 制限: {limit_seconds}s)")
start_time = time.time()
status = solver.Solve()
end_time = time.time()
duration = end_time - start_time
# 7. 結果の出力
if status in [pywraplp.Solver.OPTIMAL, pywraplp.Solver.FEASIBLE]:
state = "最適解" if status == pywraplp.Solver.OPTIMAL else "時間内での暫定解"
print(f"\n--- 結果: {state} ---")
print(f"実行時間: {duration:.4f} 秒")
print(f"使用ビン数: {solver.Objective().Value()}\n")
for j in range(num_bins):
if y[j].solution_value() > 0.5:
items_in_bin = [item_ids[i] for i in range(num_items) if x[i, j].solution_value() > 0.5]
load = sum(item_weights[i] for i in range(num_items) if x[i, j].solution_value() > 0.5)
print(f"ビン {bin_ids[j]} (容量 {bin_capacities[j]}): {items_in_bin} (合計重量: {load})")
else:
print(f"\n計算時間: {duration:.4f} 秒")
print('エラー: 解が見つかりませんでした。')
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--items', required=True)
parser.add_argument('--bins', required=True)
args = parser.parse_args()
solve_bin_packing(args.items, args.bins)
実行させてみると、60秒過ぎで停止して、その時点でのベスト解を提示してくれました。
使用ビン数は 143 とのことです。まあそんなもんですか。
AIの回答を見ると、さらに、
もしさらに大規模なデータを扱う際に、計算を高速化するための「ヒューリスティック(近似アルゴリズム)」への切り替えについても興味がありますか?
とあります。最近のAIは、こちらに質問を返すように進化していますね。そこまで言うなら、やってもらいましょう。
あります。
そのプロンプト1つで、ビンパッキング問題を高速に解くアルゴリズムとして知られている「FFD : First Fit Decreasing」のPythonコードが提示されました。
import pandas as pd
import argparse
import time
def solve_bin_packing_heuristic(items_csv, bins_csv):
# 1. データの読み込み
df_items = pd.read_csv(items_csv)
df_bins = pd.read_csv(bins_csv)
# アイテムを重い順にソート (FFDアルゴリズムの肝)
items = df_items.sort_values(by='weight', ascending=False).to_dict('records')
# ビンを容量の大きい順(または小さい順)に準備
bins = df_bins.sort_values(by='capacity', ascending=False).to_dict('records')
# 各ビンの中身を保持するリストを初期化
for b in bins:
b['current_weight'] = 0
b['items'] = []
print(f"計算開始... (アイテム数: {len(items)}, ビン候補数: {len(bins)})")
start_time = time.time()
# 2. First Fit Decreasing ロジック
unpacked_items = []
for item in items:
packed = False
for b in bins:
# 入るかどうかチェック
if b['current_weight'] + item['weight'] <= b['capacity']:
b['items'].append(item['item_id'])
b['current_weight'] += item['weight']
packed = True
break
if not packed:
unpacked_items.append(item['item_id'])
duration = time.time() - start_time
# 3. 結果の出力
print(f"--- 結果 (ヒューリスティック版) ---")
print(f"実行時間: {duration:.4f} 秒")
used_bins = [b for b in bins if len(b['items']) > 0]
print(f"使用ビン数: {len(used_bins)}\n")
for b in used_bins:
print(f"ビン {b['bin_id']} (容量 {b['capacity']}): {b['items']} (合計: {b['current_weight']})")
if unpacked_items:
print(f"\n警告: 入り切らなかったアイテム: {unpacked_items}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--items', required=True)
parser.add_argument('--bins', required=True)
args = parser.parse_args()
solve_bin_packing_heuristic(args.items, args.bins)
このアルゴリズムは、「アイテムを大きいものから順に(Decreasing)、最初に見つかった収容可能な(First Fit)ビンに入れることにする」という単純なものです。
単純なだけに、もちろん常に最適解が得られるわけではありません。ただし、抜群に高速です。
さらに、今回は「可変サイズ ビンパッキング」なので、ビンが均一ではありません。Geminiは、(とりあえず)大きいビンから試すコードを提示してきました。
pyファイルに保存して試してみると、使用ビン数は 139 となりました。MIPよりいいってどういうこと??
そういえば、CP-SATも推奨されていましたね。それも試しましょう。
CP-SATだとどうなりますか
あっという間にコードが提示されました。こちらも60秒が上限になっています。
import pandas as pd
import argparse
import time
from ortools.sat.python import cp_model
def solve_bin_packing_cpsat(items_csv, bins_csv):
# 1. データの読み込み
try:
df_items = pd.read_csv(items_csv)
df_bins = pd.read_csv(bins_csv)
except Exception as e:
print(f"エラー: {e}")
return
item_weights = df_items['weight'].tolist()
item_ids = df_items['item_id'].tolist()
bin_capacities = df_bins['capacity'].tolist()
bin_ids = df_bins['bin_id'].tolist()
num_items = len(item_weights)
num_bins = len(bin_capacities)
# 2. モデルの作成
model = cp_model.CpModel()
# 3. 変数の定義
# x[i, j]: アイテム i が ビン j に入るなら True
x = {}
for i in range(num_items):
for j in range(num_bins):
x[i, j] = model.NewBoolVar(f'x_{i}_{j}')
# y[j]: ビン j が使用されるなら True
y = {}
for j in range(num_bins):
y[j] = model.NewBoolVar(f'y_{j}')
# 4. 制約条件
# 各アイテムは必ず1つのビンに入る
for i in range(num_items):
model.Add(sum(x[i, j] for j in range(num_bins)) == 1)
# ビンの容量制限
for j in range(num_bins):
model.Add(
sum(x[i, j] * item_weights[i] for i in range(num_items)) <= y[j] * bin_capacities[j]
)
# 5. 目的関数: 使用するビンの合計コスト(今回は数)を最小化
model.Minimize(sum(y[j] for j in range(num_bins)))
# 6. ソルバーの設定と実行
solver = cp_model.CpSolver()
solver.parameters.max_time_in_seconds = 60.0 # タイムリミット設定
print(f"CP-SATで計算開始... (制限: {solver.parameters.max_time_in_seconds}s)")
start_time = time.time()
status = solver.Solve(model)
duration = time.time() - start_time
# 7. 結果出力
if status == cp_model.OPTIMAL or status == cp_model.FEASIBLE:
state = "最適解" if status == cp_model.OPTIMAL else "時間内の暫定解"
print(f"--- 結果: {state} ---")
print(f"実行時間: {duration:.4f} 秒")
print(f"使用ビン数: {solver.ObjectiveValue()}\n")
for j in range(num_bins):
if solver.Value(y[j]):
items_in_bin = [item_ids[i] for i in range(num_items) if solver.Value(x[i, j])]
load = sum(item_weights[i] for i in range(num_items) if solver.Value(x[i, j]))
print(f"ビン {bin_ids[j]} (容量 {bin_capacities[j]}): {items_in_bin} (合計: {load})")
else:
print("解が見つかりませんでした。")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--items', required=True)
parser.add_argument('--bins', required=True)
args = parser.parse_args()
solve_bin_packing_cpsat(args.items, args.bins)
CP-SATの結果は、使用ビン数 139 となりました。FFDと同じです。一応面目は保つことができた、というところでしょうか。
FLEXSCHEで逐次ナップサックで解くと
FLEXSCHE GPで、FLEXSCHEのサンプルと同様に逐次ナップサックで解くと、1秒で解けました(バージョン25.0)。
ただし、サンプル集のスケジューリングルールそのままだと 、各ビンの日時が同点で、優先順位に差が付きません。Geminiが提示したFFDのコードと同じように、数量の大きい方から解決していくことにします。
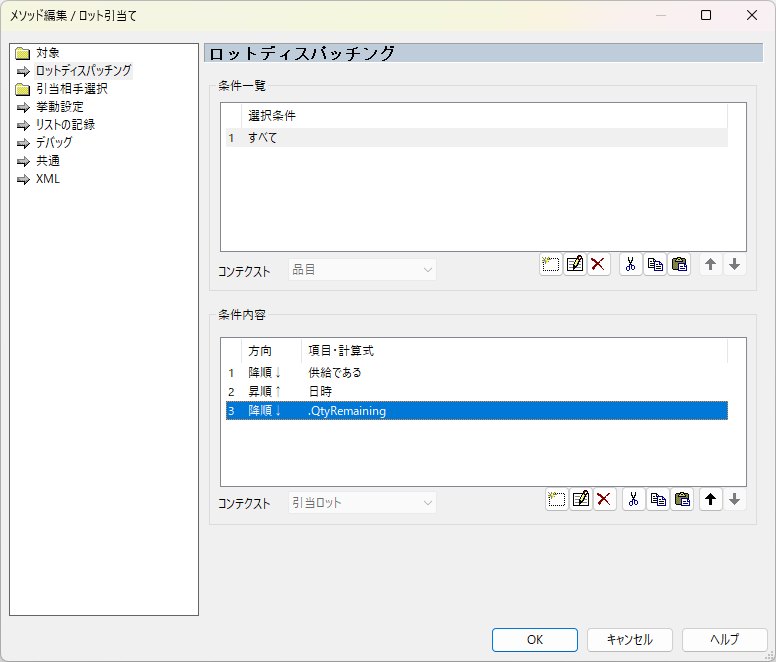
具体的には、条件内容の最後に1行追加するだけです。
これで実行すると、以下のようになりました。
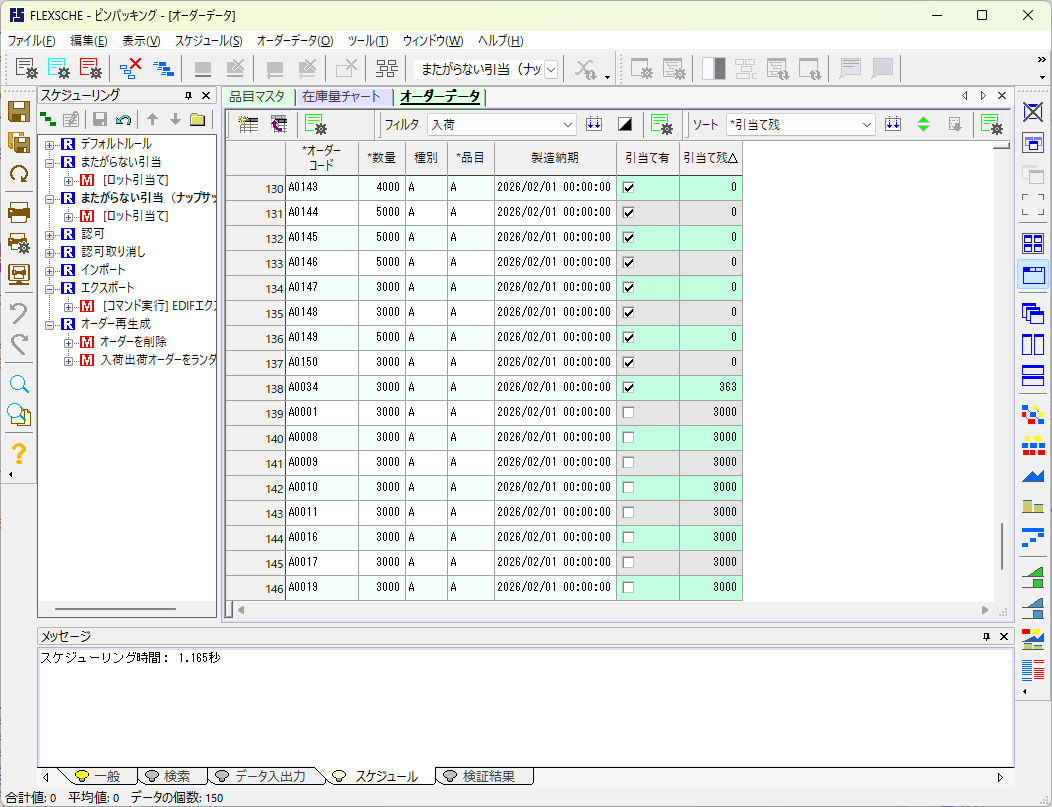
使用ビン数に相当する「引当て有 入荷オーダー数」は 138 となりました。思いがけず、一番良い結果となりました。
他のデータでも試してみるべきかもしれませんが、ともあれ、逐次ナップサックで解くのも、悪くはなさそうです。
FLEXSCHEでFFDで解くには
ちなみに、上述のサンプルのスケジューリングルール「またがらない引当」で、「ロットディスパッチング」 および 「引当相手選択/ロット選択」の二か所で、上と同様に、条件内容に1行追加すれば、それでFFDになります。
結果もPythonのFFDと同じになります。
対決結果
結果をまとめると、以下の通りです。
| 所要時間 | 使用ビン数 | |
| OR-Tools MIP | 62.4570 秒(打ち切り) | 143 |
| FFD | 0.0052 秒 | 139 |
| OR-Tools CP-SAT | 60.7443 秒(打ち切り) | 139 |
| FLEXSCHE | 1.1 秒 | 138 |
ちなみに、打ち切り時間を30分くらいに延長しても、MIPとCP-SATの結果は変わりませんでした。
ただし、もちろん特定ケースの1サンプルでの結果です。様々なデータで試せば、また異なる結果になるでしょう。
FLEXSCHE GPサンプルが逐次ナップサック問題として解く理由
なお、FLEXSCHE GPのサンプルが「可変サイズ ビンパッキング問題」を「逐次ナップサック問題」として解いている理由には、以下があります。
- 所要時間が短い
- 求められるのが厳密にはビンパッキング問題ではない
- 遠い未来はそのうち変わる
1つめは、既に説明しました。2つめ以降を説明します。
求められるのが厳密にはビンパッキング問題ではない
(可変サイズ)ビンパッキング問題では、ビンの容量やアイテムの重さはそれぞれ異なりますが、他は全て均一です。しかし、実際の生産スケジューリングでは、需要ロットにはそれぞれ納期がありますし、供給ロットにも供給可能な日時があり、多くの場合に日時を考慮する必要があります。
その点、ナップサック問題であれば、アイテムの「価値」の和を最大化することができます。それによって日時も考慮に入れることができます。
なお、上述のサンプルでも、供給側と需要側の日時の差が小さい方が価値が高い、としています。
遠い未来はそのうち変わる
生産スケジューリングの計画期間は数カ月程度になることも多いです。
数カ月先になれば、新しい注文も入ってくるでしょう。また、実際の製造が計画通りに進むとは限りません。
したがって、現在の生産スケジューリングの結果と、数カ月先の実際の状態には、ある程度の差が生じるのがむしろ普通でしょう。
その場合、長い先まで時間を掛けて「最適化」したところで、どのみち、近いうちにスケジューリングをやり直すことになります。それならば最初から近未来優先で計画しておいてもいいのではないでしょうか?
なお、この考え方は、佐藤知一さんの著書「革新的 生産スケジューリング入門」に「ゾーンメルティング法」として紹介されているものに似ています(てか、そのまんま?)。
最後に
いかがでしたか?
我々FLEXSCHEの開発陣は、日々このような感じで様々な問題と取り組んでいます。
開発したプログラムが実際に活用されて製造業の方々に喜んでいただけるのは、非常に嬉しいことです。

