能力値がひとりでに決まってくれると嬉しいですよねっ?
2021/05/20
written by 浦野 幹夫
私たちフレクシェは、20年間にわたって生産スケジューラを開発し続けてきました。20年も作り続けていれば、もうさすがにフロンティアは残っていない、かと思いきや・・・ところがまだまだあるんですね。
そのうちの一つが、生産スケジューラの導入に二の足を踏ませる高い壁を取り除く、ということです。
その「高い壁」とは、「データの整備」です。適切なモデリングとスケジューリングルールはもちろん重要ですが、それだけでは十分ではありません。精度の高いスケジュールを立案するためには、各工程で要する作業時間をできるだけ正しく見積もれるように、できるだけ妥当な「能力値」を与えてやることが求められます。
ある製品のある部品を研磨加工するために、1個当たり10分かかるのか、あるいは30分かかるのか・・・生産スケジュールはそのような見積もり(予測)の積み重ねで成り立っています。単位量の処理に要する時間をデータとして与えたもの、それが「能力値」です。どの機械で研磨するのか、誰が作業に従事するのかで作業時間が異なるのであれば、求められる精度が上がるほど、データは細かく、膨大になっていきます。
従来はそれらの能力値をいちいちデータとして与えなくてはなりませんでした。これが「高い壁」です。基幹システムにすでに情報があるならばそれを取り込むこともできますが、たとえば原価計算をするために参考にするだけであれば十分であったとしても、計画立案の根拠としては不十分かもしれませんし、そもそも生産スケジューリングの粒度とはまったく異なるかもしれません。
もちろん、ざっくりとした能力値で運用していくというのもひとつの選択であり、ある程度の成果も得られるでしょう。しかし、
「納期遅れを無くしたい」
「無駄な在庫をもっともっと減らしたい」
「残業を極力減らしたい」
「工場のスループットを大きく増やしたい」
「製造現場のドタバタを根絶したい」
など、生産スケジューラだからこそ解決できる課題を野心的に追求するためには、立案精度のさらなる向上は取り組むに値する大きなテーマといえるでしょう。
この壁を乗り越えれば大きな見返りがあることを多くの人々は知っていますが、一方で、その高さゆえに怯んでしまうのも致し方ありません。
ここで想像してみてください。最初はざっくりとした能力値だけを与えておけば、運用しているうちに次第に精度が向上していく・・・そんな仕組みがあれば、気が楽になりませんか?
これが20年目にしてフレクシェ社が遅ればせながら(ごめんなさい)取り組んだ課題であり、それを製品化したものが「FLEXSCHE DataTuner(フレクシェ・データチューナー)」です。これはまもなくリリースするFLEXSCHEバージョン20にオプション製品としてラインナップされます。
標本データを蓄積する
使うリソース(機械、設備、作業員、工具、ときには電力や作業場所など、ある作業をしている間に利用されるもの総称)によって能力は異なります。処理対象となるモノ(品目と呼びます)によっても異なります。正しく計画立案するためには、品目ごとに個々のリソースの能力値を与えなくてはなりません。
リソースの能力を知るためには、実際に作業を実行してみて計測すればわかりそうです。処理ペースが一定の自動装置であれば一回の計測で(もしくは装置の仕様書を読めば)分かるかもしれませんが、ほとんどの場合は、残念ながらそれほどシンプルではありません。ふつうは作業をするたびに「ばらつき」が生じるので、一回の計測では能力値を正しく特定することはできないでしょう。
「8畳の部屋に掃除機をかける時間」を計測することを想像してみてください。説明するまでもないですね?2分で終わることもあれば7分かかることもあるでしょう。掃除機の機種や人によって異なるでしょうし、途中で子供やペットが入ってきて邪魔をしたり、ゴミがいつもより多かったりすれば時間はさらに伸びるでしょう。そもそも測り間違えるかもしれません。
ばらつきの原因はさまざまです。
個々のリソースの種類による能力の違い、あるいは個体差
同じ作業を行うにしても、使うリソースの種類が異なれば能力は当然異なります。さらには、個体の状態(例えば当たりはずれや老朽化)によって変化することもあるでしょう。
このようなばらつきは特に人(作業員)リソースにおいては常に発生します。単純に「熟練工は一般工の1.5倍」のようなこともあれば、「Aさんは作業Pが得意だが、作業Qは不得手。Bさんはその逆。」などといったこともあり、妥当な能力値の特定が厄介な場合も多いでしょう。
処理時間の「ゆらぎ」
すべての物理現象には「ゆらぎ」は付き物です。1個のモノを同一条件下で処理するのにあるときは4分58秒、またあるときは5分8秒かかる、ということは当然のように発生し、「毎回確実に5分1秒である」ということの方がむしろ稀でしょう。特に人の作業時間には必ず大きなゆらぎを伴います。
「ゆらぎ」は、生産スケジューリングに限らず、未来を予測したり計画立案する上で不確定性の大きな要因となります。ある時点で生じたわずかなゆらぎは「バタフライエフェクト」と呼ばれる効果によって時間が進むほど大きな影響を与えることになりますが、これは工程間に適切なバッファを設けるなどしてある程度回避できます。しかし「ゆらぎ」が「妥当な能力値の測定」を困難にすることは確かです。
異常値の混入
イレギュラーなトラブルによって長引いた(異常に早かった、ということもあるかもしれませんが)作業をどのように扱うかは、意外と難しい問題です。実績収集時に「今回は異常だった」という情報を明確に与えられればよいのですが、客観的な判定が難しいことも少なくないでしょう。
そこでデータを集めて自動判定することが理想なのですが、「本来の能力」を事前に知らない場合、どのような値を「異常値(外れ値)」とみなすべきでしょうか。異常値検出の理論はいくつか存在しますが、私が試してみた限りでは(少なくともスケジューリング目的での利用においては)いまひとつ満足のいくものは見つかりませんでした。そこで、既存の理論をカスタマイズした独自の判定方法を利用します。
なお、確率的に発生しうるトラブルをも織り込んで能力を推定すべきだという考え方もありますが、ひとまずは保留しておきます。
単なる入力ミス
実績をキーボードから入力するような運用では"10"とすべきところを"100"としてしまうミスはしばしば起こり得るでしょう。このように明らかな差であれば異常値として除外できますが、例えば"212"を誤って"221"と入力してしまうとおそらく区別のしようがありません。
対処方法は、人為ミスが発生しづらいシステムを利用することくらいでしょうか。例えば、数値をバーコードで読み取ったり、作業開始時と終了時にボタンを押すだけで日時を入力したり、というような仕組みならば、ヒューマンエラーを回避できるでしょう。
これほどに様々なばらつき要因があっては、計画の根拠とすべき「時間」を直接的に測定できそうもありません。そこで、複数回の測定結果を統計的に処理して、妥当といえる単一の能力値を「推定」し、それに基づいて未来の計画立案をすることになります。
能力を推定するためには、それなりの個数の標本データが必要です。とはいえ事前に何度も測定してから推定するというわけにもいかないので、本番の作業結果を使って推定することになります。まずは初期値としてある程度ざっくりとした能力値を与えておいて、運用サイクルを回しながら標本データを集めて、それらを蓄積しながら徐々に推定していく、という流れになります。
工程内での内訳を分析する
推定すべきものは単にリソースの能力値だけではありません。
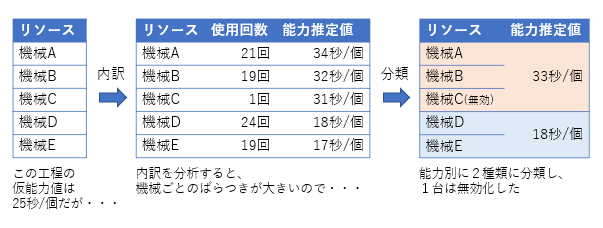 ある工程で利用可能な複数のリソースに単一の能力値を初期値として仮に与えていたが、実はバリエーションがあった、ということもあるでしょう。図の例では、ある工程で利用できる5台の機械に1個あたり25秒という仮の能力値をざっくりと与えていましたが、実績に基づいて推定してみたところ、1個当たり30秒以上かかる遅い機械と20秒以下の2つのグループに分けられることが分かりました。
ある工程で利用可能な複数のリソースに単一の能力値を初期値として仮に与えていたが、実はバリエーションがあった、ということもあるでしょう。図の例では、ある工程で利用できる5台の機械に1個あたり25秒という仮の能力値をざっくりと与えていましたが、実績に基づいて推定してみたところ、1個当たり30秒以上かかる遅い機械と20秒以下の2つのグループに分けられることが分かりました。
また、機械Cは実際にはほとんど使われないことも推定できました。スケジューラーがそのような資源に指図を出して現場で毎回訂正するようでは、計画の実行可能性(feasibility)と信頼性を損なってしまうので、計画から除外した方がよいのかもしれません。
ここでひとつ大切なのは、これらを自動判定をするのではなく、人の判断を介在させられるようにするということです。上の例において、機械Cは最近たまたま使われていなかっただけだという場合に、高々数十件のデータを根拠にいつのまにか計画から除外されてしまうことは好ましくありません。長期間にわたる膨大なデータに基づくのであれば完全自動化も許容できるかもしれませんが、多品種で製品ライフサイクルの短い製造業ではそれを待つ余裕はないでしょう。
パラメタ化された能力
もう一歩、先へ進んでみましょう。
例えば、複雑さだけが異なる類似の6種類の部品を加工する工程(工程1~工程6)と、それを加工するためのスキルレベルが異なる6名の作業員(作業員1~作業員6)がいるとしましょう。
これを愚直にモデリングすると、6個の工程を個別に定義して、個別の能力値を与えられた6人の作業員を利用可能なリソースとして結びつけることになるでしょう。この場合、トータルで36個の能力値がばらばらに存在することになります。
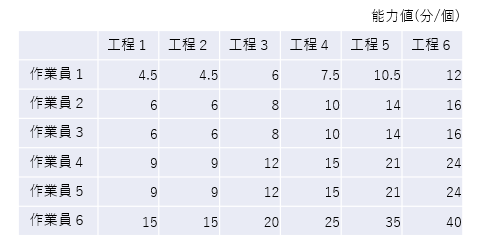 すべての正しい値が事前に分かっているのであればこれで問題はありませんが、実績データに基づいてこれから推定するのであれば、良い作戦ではありません。
すべての正しい値が事前に分かっているのであればこれで問題はありませんが、実績データに基づいてこれから推定するのであれば、良い作戦ではありません。
というのは、蓄積できるデータに偏りがあると、いつまでも推定できない組み合わせが残るかもしれません。例えば、トータルでは十分多くのデータを蓄積できているのに、たまたま作業員1と工程1の組み合わせについては標本データが無いとします。すると、作業員1による他の工程の作業実績や、他の作業員による工程1の作業実績がどんなに潤沢にあっても作業員1と工程1の組み合わせだけはチューニングできません。もったいないですね。
これは、複雑な部品は誰が加工しても余分に時間がかかり、また熟練度が高い人は何を加工しても他の人より早い、というような相関性が活かされていないためです。もし作業員1以外による工程1の加工時間のデータが十分に得られ、他の部品の数倍時間がかかることが分かったのであれば、作業員1による工程1の加工時間も相応に長くなることは推定されてしかるべきでしょう。
そこで、モデリングを工夫します。
「加工の複雑さ」を各工程の(リソースに依らない)能力値として与え、「作業員のスキルレベル」を作業員リソースのスキル値として与えます。そして、工程と作業員の組み合わせで決まる能力値をスキル係数で割ったものを作業時間とするように定義します(これはFLEXSCHEで簡単にできます)。
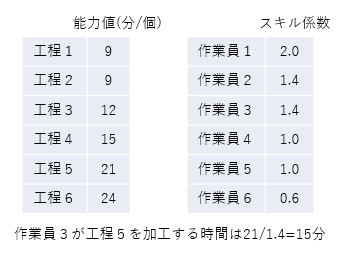 この先のロジックは少々複雑なので省略しますが、ある組み合わせについての直接のデータが無くても、これら12個の数値が推定できれば、すべての組み合わせでの作業時間を推定することができます。チューニング対象となる値も36個から12個に減っているので、見通しが良くメンテナンスもしやすくなります。値が6個と6個では対象が3分の1になるだけですが、50個と20個ならば (50+20) / (50×20) =100分の7になります。
この先のロジックは少々複雑なので省略しますが、ある組み合わせについての直接のデータが無くても、これら12個の数値が推定できれば、すべての組み合わせでの作業時間を推定することができます。チューニング対象となる値も36個から12個に減っているので、見通しが良くメンテナンスもしやすくなります。値が6個と6個では対象が3分の1になるだけですが、50個と20個ならば (50+20) / (50×20) =100分の7になります。
言い換えると、無駄に取っ散らかって収集が付かなくなることを避けられます。
もちろんこの方法は自由度を犠牲にします。相関性を前提としたモデリングなので、「作業員1はどんな部品でも同じ時間で加工できるが、作業員2は部品によって得手不得手がある」というような状況は表せないので、万能ではありませんが、臨機応変に作戦を選べばよいでしょう。
このようなモデリングは「パラメタ化」と呼ばれるもので、生産スケジューラでは多用される便利な方法です。データ量を減らしたり、再利用したりするのに効果があります。
ここでちょっと込み入った話を。
この例では工程の能力値とリソースのスキル係数という2つの「次元」から成る「2次元キューブ構造」にデータを配置して分析します。ほとんどすべての運用ではこの範囲に収まると私たちは考えていますが、完成品固有のパラメタなど、それ以上の要因が作業時間の算出に関わる場合にも対応するために、FLEXSCHE DataTunerは4次元キューブ構造までサポートします。
データチューナーをリリースします!
私たちがデータチューニング機能のニーズを認識してから久しいですが、具体的な構想と設計に着手したのは一昨年まで遡ります。次第にデータチューナーを実現するための仕組みが明らかになり、試行錯誤の末にようやくここまでたどり着きました。
データチューナーは以下のように使います。
- 十分な時間をかけて多くの作業実績データに基づく標本データを蓄積する
- 蓄積データからノイズを除去して統計的に処理する
- データを構造化して分析し、本来あるべき能力値を推定する
- 各パラメタを推定値で更新するかどうかを人が決める
データチューナーの分析処理と推定値の提示までは自動ですが、マスターデータの値を勝手の更新することはありません。それぞれの推定値ごとに「推奨度」が提示されるので、それを参考に各推定値を採用するかどうかをユーザーに判断していただきます。多次元においてはどの推定値を適用すべきかを即座には判断しがたいので、推奨度は頼りになるでしょう。
ところで、「計画が狂う」という言い回しがありますが、もちろん実際には計画が狂うわけではなく、「現実が変動する」のです(もちろんもともとの計画が見当違いだったという場合もありますが)。トラブルやゆらぎなどによって製造現場は「必ず」変動するので、どんなに緻密に立案しても(あるいは高度に最適化しようとも)それはあくまで「計画」であり、変動する現実世界を「予知」できるはずもありません。計画立案と計画遂行が目指すのは、「各作業を計画どおりに遂行すること」ではなく、全体として「計画どおりの量(→スループット)とタイミング(→納期)を維持しながら生産し続けること」です。
そのためには、変動を前提としつつ、それに「適応」しながらも量とタイミングをしっかりと守り続けることに尽きます。そのためには「(確率的に妥当な)生産能力を正しく見積もれること」が必要条件です。見積もりが高過ぎればどんなに頑張っても工場は責任を果たせませんし、低過ぎれば能力を無駄にしてしまいます。正しい能力値に基づいた計画立案が不可欠であり、そのための製品がFLEXSCHE DataTunerです。
「変動への適応」を担う製品はFLEXSCHE CarryOutです。このふたつが両輪となって立案と遂行のサイクルを回すことができれば、多くの課題を解決するための準備が整うでしょう。
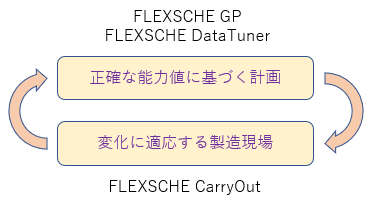 なお、FLEXSCHE DataTunerで蓄積すべき実作業時間はFLEXSCHE CarryOutでも収集できるので一石二鳥ですね。
なお、FLEXSCHE DataTunerで蓄積すべき実作業時間はFLEXSCHE CarryOutでも収集できるので一石二鳥ですね。
私の次回のブログでは、最新作FLEXSCHE DataTunerを具体的にご紹介したいと思います!

